Managed Services: Overview
Jade Networks helps companies with the design, implementation, deployment, management and outsourcing of enterprise networks. We also help in areas including disaster planning and recovery, policy planning and analysis, network and vulnerability assessment, network automation, and others. Our managed services focus on both the operational and security aspects of enterprise networks. We break these services apart into Security, Monitoring, and Analysis/Response Systems however all are tightly related and are treated separately for descriptive purposes only.
We are also actively involved in designing and building new security tools. The Jade Unified Security Framework (USF) is a thin extendable security layer providing easy to use hooks for applications and security components to control network security settings. The first version of the USF is complete and in use and includes tools for the manipulation of firewall IP block rules (timed and static) by any machine on the network. Command line tools are also provided to run and maintain the Jade DNSBL spam defense. These tools provide the basic network hooks needed to easily communicate and configure network routers, switches, IPS and other systems. The second version of the USF will have tighter SIEM and IDS integration.
We believe in taking a “business first” approach to network design, monitoring, and administration. By first understanding business objectives, proper security and operational policies can be put in place followed by the systems and software needed to enforce them. Many organizations, either in their attempt to patch newly discovered vulnerabilities, poorly defined budgets, or limited expertise in the field tend to get this order backwards. This often results in inadequate security and operational controls as well as a higher TCO for the organization.
We work with clients through our consulting services to build simple security and operational policies which match their business objectives. We take these clearly defined policies to establish more concrete procedures and plans to implement and deploy solutions. This phase typically takes into consideration technical, procedural, administrative, physical and people (staff, partners, vendors, customers) issues. By first understanding the environments (threats, risks, vulnerabilities, and countermeasures) we then come up with appropriate solutions with a proper balance of security, cost, business objectives, availability, and usability. The end result are enterprise networks which are managed for both security and operational analysis and response.
Once the policies and designs are in place we work with customers to implement the enterprise management systems. These systems can be located either at the customer datacenter and/or the Jade Networks datacenter. The active monitoring of these systems (people) can also be any combination of customer and Jade provided resources depending on the needs of the customer. When designing and building these systems we automate the response systems whenever practical to decrease administrator response time, increase overall service availability, and decrease operational costs.
The information that follows on this page and the more detailed pages on Security, Monitoring, and Analysis and Response systems is intended to present an introduction to these topics and how they relate to each other. We hope that the general introductory information presented here can be useful in forming a basic foundation and basis for building solutions catering to the unique needs of each customer. What is presented, like the rest of the security industry, is subject to change as threats and solutions continue to evolve. For more information on how we can work together or on any of the material presented here contact us.
Security
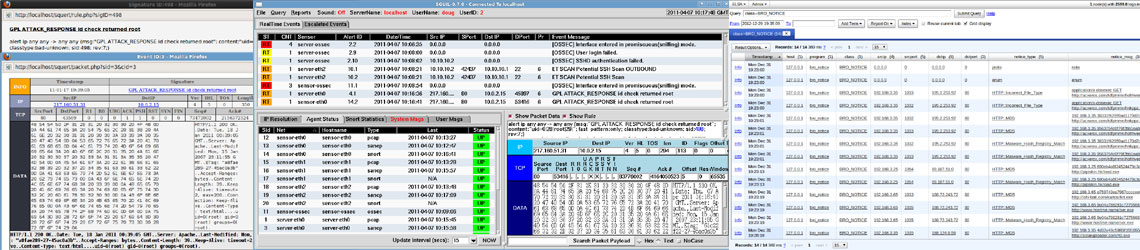
 Security, in it’s many forms, is a hot topic today. We’ve all heard about how criminals wreak havoc on companies and individuals many ways, including identity theft, denial of service (DOS) attacks, viruses and worms, and many more. They exploit vulnerabilities anywhere they can find them, from the lower network layers up to the applications and social networking. It is critically important for companies and individuals to take these threats seriously and protect themselves where they can.
Security, in it’s many forms, is a hot topic today. We’ve all heard about how criminals wreak havoc on companies and individuals many ways, including identity theft, denial of service (DOS) attacks, viruses and worms, and many more. They exploit vulnerabilities anywhere they can find them, from the lower network layers up to the applications and social networking. It is critically important for companies and individuals to take these threats seriously and protect themselves where they can.
Securing network assets and information can be a very complex and time consuming endeavor. Nothing is sacred to the criminals wanting to exploit an organization or its resources. Motives include direct financial gain (theft), abusing resources as an attack base against other organizations, theft of services (DOS), and targeting of corporate information and/or users. All infrastructure elements, including the human ones, need to be addressed to provide true protection. Vulnerabilities anywhere can provide the criminal the opening they need to gain access.
When we discuss managed security we combine traditional security with operational management. Many of the controls necessary to monitor and manage one can be applied to the other. Security is clearly critically important however so is maintaining operational integrity. Having adequate security but not being able to keep services running misses the point of building enterprise networks in the first place. Our focus is managing networks which are both secure and perform at or above the levels needed.
Threats and attacks can come from anywhere and at anytime. It only takes one successful breach to put an organization at risk so all attack surfaces need to be protected. There is no single way to protect an enterprise as most countermeasures target a specific class of attacks. A proper security framework breaks the problem down by type and establishes defense layers which are then managed separately. It’s possible to break security down many different ways however for our purposes we focus on the following areas: physical security, network security, application security, operating systems, and social engineered attacks.
The first step in establishing a suitable security framework is evaluating what needs to protected (sorted by priority) and then determining how these assets might be compromised (vulnerabilities). Countermeasures can then be established consistent with the corporate security policy. Some attacks can be detected as they occur. For these either the machine or application detecting the attack can act on their own, or they can log the attack for later detection and formal incident generation by an external monitoring system. Sometimes both approaches may be taken for a detected problem.
Once we know what to look for and where the threats might come from it is important to match these with systems or processes which at a minimum will detect and report anomalies. Network stack attacks are best detected with packet monitoring IPS systems and/or within the host operating systems. Authentication attacks can sometimes be detected the same way but often are best discovered at the application layer (the service being attacked rather than the network infrastructure). Protocol specific attacks need to be detected by the application responsible for the service. All threats should communicate problems back to the appropriate network management and/or SIEM monitoring back-ends for recording, analysis, correlation, and response.
Getting all the infrastructure elements properly communicating with the desired back-end systems is the first half of building the solution. Many of these communicate using standard protocols such as syslog. Others use their own local logging formats which need to be translated and then fed into the monitoring back-end. Others may need glue scripts or programs written to link everything correctly.
The next step is what to do once a threat has been identified. For most situations alerts should be sent out to the responsible administrators letting them know. Increasingly we find that the better we can define the threat, the higher the probability we can then formulate an automated response to this threat. For conditions that result in the execution of well defined procedures, these can be codified and called automatically upon detection. The automation of response systems is an extremely powerful tool that results in systems that can not only detect when problems exist, but systems that fix themselves as they occur. Systems run better with less down time and administrators can focus their precious resources on more critical issues.
For more detailed information on security, please see our Managed Services: Security page.
Monitoring
 Monitoring systems actively collect, store, analyze, display and act upon data related to the enterprise networks (network components, servers, devices, applications, workloads, etc). They monitor applications, interfaces, protocol (service) availability, operating system processes, devices, and more. What is not built into the platform can usually be added through simple scripts. If you can write a script to check on something it is trivial to integrate it into the system to track. Information gathered is used in the daily administration of the enterprise network, performance and fault analysis, capacity planning, and more.
Monitoring systems actively collect, store, analyze, display and act upon data related to the enterprise networks (network components, servers, devices, applications, workloads, etc). They monitor applications, interfaces, protocol (service) availability, operating system processes, devices, and more. What is not built into the platform can usually be added through simple scripts. If you can write a script to check on something it is trivial to integrate it into the system to track. Information gathered is used in the daily administration of the enterprise network, performance and fault analysis, capacity planning, and more.
Network Management systems are the typical tools used for this purpose and provide the following functionalities: discovery, monitoring, performance analysis, device management, and event management (intelligent notifications or customized alerts). Most monitoring solutions come with integrated data visualization tools, anomaly detection, and incident reporting/action tools. The later are the building blocks for creation of automated response systems.
Visualization tools allow for the time based graphical display of the collected data. Most visualization tools allow for not only combining of data as needed but also the application of basic statistical rules. Being able to observe enterprise network behavior graphically and with multiple views gives the administrator insights into operations and security that were previously unavailable.
Being able to detect problems as they occur and do something meaningful is one of the main reasons we use monitoring systems (or perform most administrative tasks). They provide the tools used to define the symptoms problematic events, and then once detected what actions to take. The configuration of conditions or expressions defining problematic situations called an event or trigger. When trigger conditions are met administrator defined actions are taken. These can be anything from notification messages (alerts) to the running of automated scripts or programs designed to correct the problem (without administrator intervention). The automation of response systems is one of the most powerful tools of these types of systems.
Discovery is the process by which new devices or services are found. Discovery can be configured to automatically add new assets to the management system as they are found. This can greatly speed up management deployment and simplify administration. Modeling of devices is the defining of characteristics and attributes to monitor that are common to all assets of the same type. Models are commonly stored in templates which are then referenced when defining new devices to add to the network, further simplifying the device addition process and saving time.
For more detailed information on monitoring and also a comparison between Network Management and SIEM Systems, please see our Managed Services: Monitoring page.
Analysis and Response Systems
 Collecting operational data is great but the real power of these systems is their ability to analyze collected data to detect, alert, and resolve anomalies. The ability to analyze and react to problems is found in many products ranging from security, monitoring, SIEM, applications and custom built tools. For problems that can be anticipated and which their solution is well understood it is usually possible to codify the resolution in a program or script which can be invoked upon detection. This type of response system automation creates much more reliable systems that can react in real-time to problems without direct operator involvement, reducing costs and resulting in much higher application availability.
Collecting operational data is great but the real power of these systems is their ability to analyze collected data to detect, alert, and resolve anomalies. The ability to analyze and react to problems is found in many products ranging from security, monitoring, SIEM, applications and custom built tools. For problems that can be anticipated and which their solution is well understood it is usually possible to codify the resolution in a program or script which can be invoked upon detection. This type of response system automation creates much more reliable systems that can react in real-time to problems without direct operator involvement, reducing costs and resulting in much higher application availability.
Data Collection
Security and operational information can come from any device or sensor on the network. Some of these sources directly log information using standard network protocols such as syslog. Others can be polled for their status using protocols like SNMP. Some applications, for example the Apache Web Server, do not directly use reporting protocols but log their information directly using local logfiles. Other applications or services may do none of the above and need to be directly queried to determine their status.
Network Management systems typically collect their own data through observation or polling of devices and sensors. SIEM systems rely upon computer generated data which they process to understand the world around them. Both of these monitoring solutions need to filter and then normalize, or convert the information into a standard internal format for storage and later use. The amount of data generated by modern systems can be massive. Having all this data spread across the network is not only undesirable but defeats the purpose of systems designed to monitor, analyze, and correlate all enterprise network activity. One of the most basic features of SIEM systems is logfile aggregation – the collecting, combining, filtering, converting, and storing of enterprise logging data in a centralized location. Once the data has been collected and is in a usable format, systems can then analyze it either in real-time for ongoing threats or later for historical analysis.
Analysis
SIEM systems combine logging data with other data sources such as database activity monitoring, netflow, file integrity monitoring and threat intelligence feeds. They then establish context, analyze, correlate, prioritize and present the findings in reports and graphically. Forensics tools further augment these capabilities. Not only can these solutions detect threats in a single stream (authentication attacks against a single SMTP or IMAP server for example), but can see threats across the entire enterprise. Real time analysis is applied across the enterprise resulting in more informed decisions and the ability to detect and react to a far greater number of attacks. Non-real time analysis can be done off-line, potentially by a different SIEM server, to analyze a much bigger dataset spanning more resources and/or time windows. This provides additional insights to threats against the enterprise as not all threats occur within a small window of time and are self-contained.
Other common uses for SIEM solutions are for compliance reporting, historical analysis and incident investigation. When combined with packet capture (in tandem with an IDS/IPS solution) very sophisticated and thorough forensic analysis is possible.
Response Systems
 It is critical that any monitoring solution be able to react to detected threats in real-time. Most SIEM solutions are able to perform predefined actions to mitigate a detected threat. Not all however have the ability to invoke customer supplied programs or scripts. This ability in our opinion is essential to solutions we provide as it forms the basis for building an extensible automated response system.
It is critical that any monitoring solution be able to react to detected threats in real-time. Most SIEM solutions are able to perform predefined actions to mitigate a detected threat. Not all however have the ability to invoke customer supplied programs or scripts. This ability in our opinion is essential to solutions we provide as it forms the basis for building an extensible automated response system.
Just as with Network Management systems, SIEM triggers can invoke alerts or notifications upon detection. The proper design of alert notifications helps keep administrators informed about changes to the network. This is particularly important for anomalies which are not expected and for which no automated response mechanisms have been established.
Many operational problems and common security threats are well understood. Examples include hung servers or applications, application authentication attacks, and other situations which are frequently encountered. When the mitigation of these problems can be codified with a very high degree of certainty (near or at 100%), automated solutions can be put in place. Common responses to threats include service restart, machine reboot, and blocking the attacking IP addresss/network or user. Depending on the network capabilities applied blocks can be permanent or time limited.
The ability to be able to write custom programs or scripts to mitigate problems is in our opinion one of the most important capabilities to look for in any SIEM or Network Management solution. Being able to react and correct problems quickly and automatically ensures much higher service availability to customers and lets overworked administrators better sleep through the night. Instead of being on call to deal with every problem, most can be automated and alerts sent to the administrator informing them of what happened and the action taken.
For more detailed information on analysis and response systems, please see our Managed Services: Analysis and Response Systems page.